11. Mai 2021
- Gartner-Kunde? Log in und personalisierte Ergebnisse entdecken.
Data Fabric Architecture ist der Schlüssel zur Modernisierung von Datenmanagement und -integration
Verfasst von: Ashutosh Gupta
D&A-Führungskräfte sollten die wichtigsten Säulen der Data Fabric Architecture verstehen, um eine maschinenfähige Datenintegration zu realisieren.
Die Agilität der Datenverwaltung ist für Unternehmen in einer zunehmend vielfältigen, verteilten und komplexen Umgebung zu einer unternehmenskritischen Priorität geworden. Um menschliche Fehler und die Gesamtkosten zu reduzieren, müssen die Führungskräfte im Bereich Daten und Analysen (D&A) über die traditionellen Datenverwaltungspraktiken hinausgehen und sich modernen Lösungen wie der KI-gestützten Datenintegration zuwenden
„Das aufkommende Konzept der „Data Fabric“ kann eine robuste Lösung für die allgegenwärtigen Herausforderungen des Datenmanagements sein, wie z. B. die kostenintensiven Datenintegrationszyklen mit geringem Wert, die häufige Wartung früherer Integrationen, die steigende Nachfrage nach Echtzeit- und ereignisbasiertem Datenaustausch und mehr“, sagt Mark Beyer, Distinguished VP Analyst bei Gartner.
E-Book herunterladen: The Future of Decisions
Was ist Data Fabric?
Gartner definiert Data Fabric als ein Designkonzept, das als integrierte Schicht (Fabric) von Daten und Verbindungsprozessen dient. Eine Data Fabric nutzt kontinuierliche Analysen über vorhandene, auffindbare und referenzierte Metadatenwerte, um die Entwicklung, Bereitstellung und Nutzung integrierter und wiederverwendbarer Daten in allen Umgebungen, einschließlich hybrider und Multi-Cloud-Plattformen, zu unterstützen.
Data Fabric nutzt sowohl menschliche als auch maschinelle Fähigkeiten, um auf Daten vor Ort zuzugreifen oder gegebenenfalls deren Konsolidierung zu unterstützen. Es identifiziert und verbindet kontinuierlich Daten aus unterschiedlichen Anwendungen, um einzigartige, geschäftsrelevante Beziehungen zwischen den verfügbaren Datenpunkten zu erkennen. Die Einblicke ermöglichen eine verbesserte Entscheidungsfindung und bieten durch den schnellen Zugriff und das schnelle Verständnis mehr Wert als herkömmliche Datenverwaltungspraktiken.
So können beispielsweise Supply-Chain-Führungskräfte, die eine Data Fabric verwenden, neu entdeckte Datenwerte schneller zu bekannten Beziehungen zwischen Lieferantenverzögerungen und Produktionsverzögerungen hinzufügen und Entscheidungen mit den neuen Daten (oder für neue Lieferanten oder neue Kunden) verbessern.
Mehr lesen: Die 10 wichtigsten Trends für Data und Analytics von Gartner für 2021
Betrachten Sie Data Fabric als ein selbstfahrendes Fahrzeug
Es gibt zwei Szenarien. Im ersten Szenario ist der Fahrer aktiv und achtet vollkommen auf die Strecke, und das autonome Element des Fahrzeugs hat minimale oder keine Funktion. Im zweiten Szenario ist der Fahrer etwas träge und verliert die Konzentration, woraufhin das Fahrzeug sofort in einen halbautonomen Modus schaltet und die notwendigen Kurskorrekturen vornimmt.
Beide Szenarien zeigen, wie Data Fabric funktioniert. Es überwacht die Datenpipelines zunächst als passiver Beobachter und beginnt dann, Alternativen vorzuschlagen, die die Produktivität erhöhen. Wenn sowohl der Daten-„Treiber“ als auch das Machine Learning mit sich wiederholenden Szenarien vertraut sind, ergänzen sie sich gegenseitig, indem sie improvisierte Aufgaben (die zu viele manuelle Stunden in Anspruch nehmen) automatisieren, während sich die Führung auf die Innovation konzentrieren kann.
Mehr lesen: Datenaustausch als Geschäftsnotwendigkeit, um das Digital Business zu beschleunigen
Was D&A-Führungskräfte über Data Fabric wissen sollten
- Data Fabric ist nicht nur eine Kombination aus traditionellen und modernen Technologien, sondern ein Designkonzept, das den Schwerpunkt der menschlichen und maschinellen Arbeitsbelastung verändert.
- Die neuen und aufkommenden Technologien wie semantische Wissensgraphen, aktives Metadatenmanagement und integriertes Machine Learning (ML) sind erforderlich, um das Data Fabric Design zu realisieren.
- Das Design optimiert die Datenverwaltung durch die Automatisierung sich wiederholender Aufgaben, wie z. B. die Profilerstellung von Datensätzen, das Erkennen und Anpassen von Schemata an neue Datenquellen und – in der fortgeschrittensten Version – die Sanierung fehlgeschlagener Datenintegration.
- Keine bestehende Einzellösung kann eine vollwertige Data Fabric Architektur ermöglichen. Die D&A-Führungskräfte können mit einer Mischung aus selbst entwickelten und gekauften Lösungen eine beeindruckende Data Fabric Architecture sicherstellen. Sie können sich beispielsweise für eine vielversprechende Datenverwaltungsplattform entscheiden, die 65 bis 70 % der erforderlichen Funktionen bietet, um eine Data Fabric zusammenzufügen. Die fehlenden Funktionen können mit einer selbst entwickelten Lösung erreicht werden.
Wie können D&A-Führungskräfte eine Data Fabric Architecture bereitstellen, die einen Geschäftswert liefert?
Um den Geschäftswert durch das Data Fabric Design zu steigern, sollten D&A-Führungskräfte für eine solide technologische Basis sorgen, die erforderlichen Kernfunktionen identifizieren und die vorhandenen Tools zur Datenverwaltung bewerten.
Mehr lesen: Wie DataOps den Geschäftswert von Daten und Analysen steigert
Hier sind die wichtigsten Säulen einer Data Fabric Architecture, die D&A-Führungskräfte kennen sollten.
Nr. 1: Data Fabric muss alle Formen von Metadaten sammeln und analysieren
Kontextbezogene Informationen bilden die Grundlage für ein dynamisches Data Fabric Design. Es sollte einen Mechanismus geben (z. B. einen gut vernetzten Pool von Metadaten), der es der Data Fabric ermöglicht, alle Arten von Metadaten zu identifizieren, zu verbinden und zu analysieren, z. B. technische, geschäftliche, betriebliche und soziale.
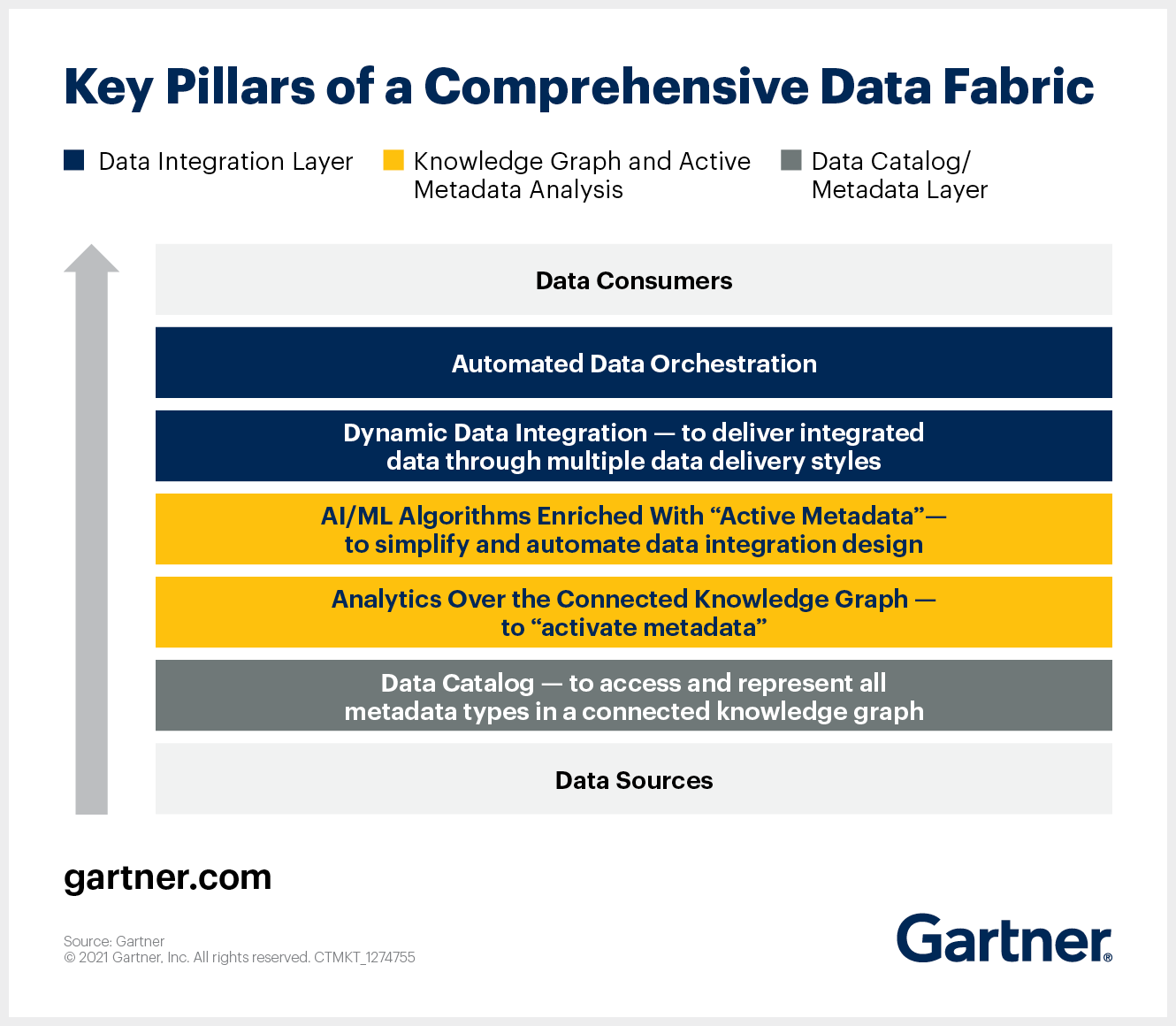
Nr. 2: Data Fabric muss passive Metadaten in aktive Metadaten umwandeln
Für einen reibungslosen Datenaustausch ist es für Unternehmen wichtig, Metadaten zu aktivieren. Um dies zu erreichen, sollte Data Fabric:
- Verfügbare Metadaten kontinuierlich auf wichtige Metriken und Statistiken hin analysieren und dann ein Graphenmodell erstellen.
- Metadaten auf der Grundlage ihrer eindeutigen und geschäftsrelevanten Beziehungen grafisch in leicht verständlicher Weise darstellen.
- Wichtige Metadatenmetriken nutzen, um KI/ML-Algorithmen zu ermöglichen, die mit der Zeit lernen und fortschrittliche Vorhersagen in Bezug auf Datenmanagement und -integration treffen.
Nr. 3: Data Fabric muss Wissensgraphen erstellen und kuratieren
Mit Wissensgraphen können Führungskräfte aus Daten und Analysen einen Geschäftswert schöpfen, indem sie Daten mit Semantik ergänzen.
Die semantische Ebene des Wissensgraphen macht ihn intuitiver und einfacher zu interpretieren, was die Analyse für die D&A-Führungskräfte erleichtert. Es verleiht dem Datenverwendungs- und Inhaltsgraphen eine gewisse Tiefe und Bedeutung, so dass KI/ML-Algorithmen die Informationen für Analysen und andere betriebliche Abläufe verwenden können.
Integrationsstandards und -tools, die regelmäßig von Datenintegrationsexperten und Dateningenieuren verwendet werden, können einen einfachen Zugriff auf einen Wissensgraphen – und dessen Bereitstellung – gewährleisten. D&A-Führungskräfte sollten dies nutzen; andernfalls kann es bei der Einführung von Data Fabric zu zahlreichen Unterbrechungen kommen.
Nr. 4: Die Data Fabric muss über ein robustes Datenintegrations-Rückgrat verfügen
Data Fabric sollte mit verschiedenen Arten der Datenbereitstellung kompatibel sein (einschließlich, aber nicht beschränkt auf ETL, Streaming, Replikation, Messaging und Datenvirtualisierung oder Daten-Microservices). Es sollte alle Arten von Datenbenutzern unterstützen – dazu gehören IT-Benutzer (für komplexe Integrationsanforderungen) und geschäftliche Benutzer (für Self-Service-Datenvorbereitung).

Erleben Sie Konferenzen für [Funktionsbereich]
Seien Sie dabei, wenn auf den Gartner-Konferenzen die neuesten Insights bekannt gegeben werden.
Empfehlenswerte Ressourcen für Gartner-Kunden:*
Data Fabrics fügen erweiterte Intelligenz hinzu, um Ihre Datenintegration zu modernisieren
Neue Technologien: Data Fabric ist die Zukunft der Datenverwaltung
*Achtung: Einige Dokumente stehen möglicherweise nicht allen Gartner-Kunden zur Verfügung.